
This is the transcript of the video talk Smarter code editors, ep05 - Collapse blocks, expand function calls published 2021-03-02
<< Back to index
Welcome back to these short talks on improving our programming tools. If you want a proper introduction, watch the first episode in the series. Otherwise, let's dive right in.
Today's talk is about a classic debate or dilemma in the programming world - writing many small functions vs writing few large functions - and it's about my attempt at tackling this dilemma through tool design.
First, I'll briefly describe the dilemma, then review a bunch of existing editors to see which features they already provide to help us deal with the dilemma. Then I'll explain my ideas and demonstrate with a prototype, and finally suggest future work - things I haven't solved yet.
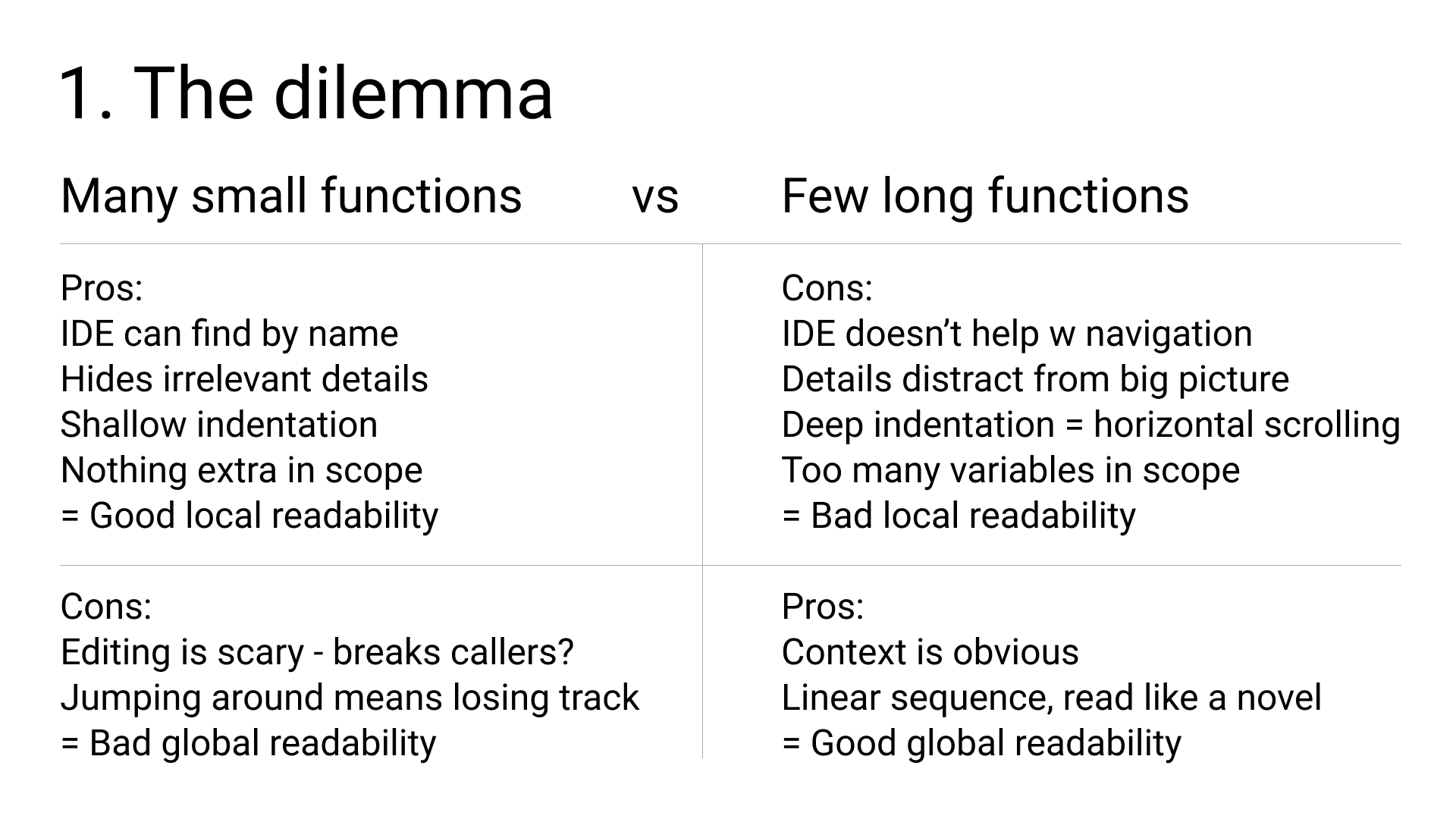
There's a classic piece of advice or rule of thumb that programmers tell each other. It says to keep your functions no longer than 10 lines or 20 lines or sometimes no longer than "a page", which of course varies with your screen and font size. Then there are others who advocate for a much more fine-grained split, for example the well-known programmer and author Uncle Bob in this blog post.
There are yet others who advocate that long functions are perfectly ok and that your criteria for splitting them up shouldn't be based on length, but on other factors, for example cyclomatic complexity, or just re-use. To only turn a piece of code into a function if you need to use it in more than one place. So there is contradictory advice, for different styles.
People then debate which style is best. If you want examples, I've linked three such discussion threads on Hacker News:
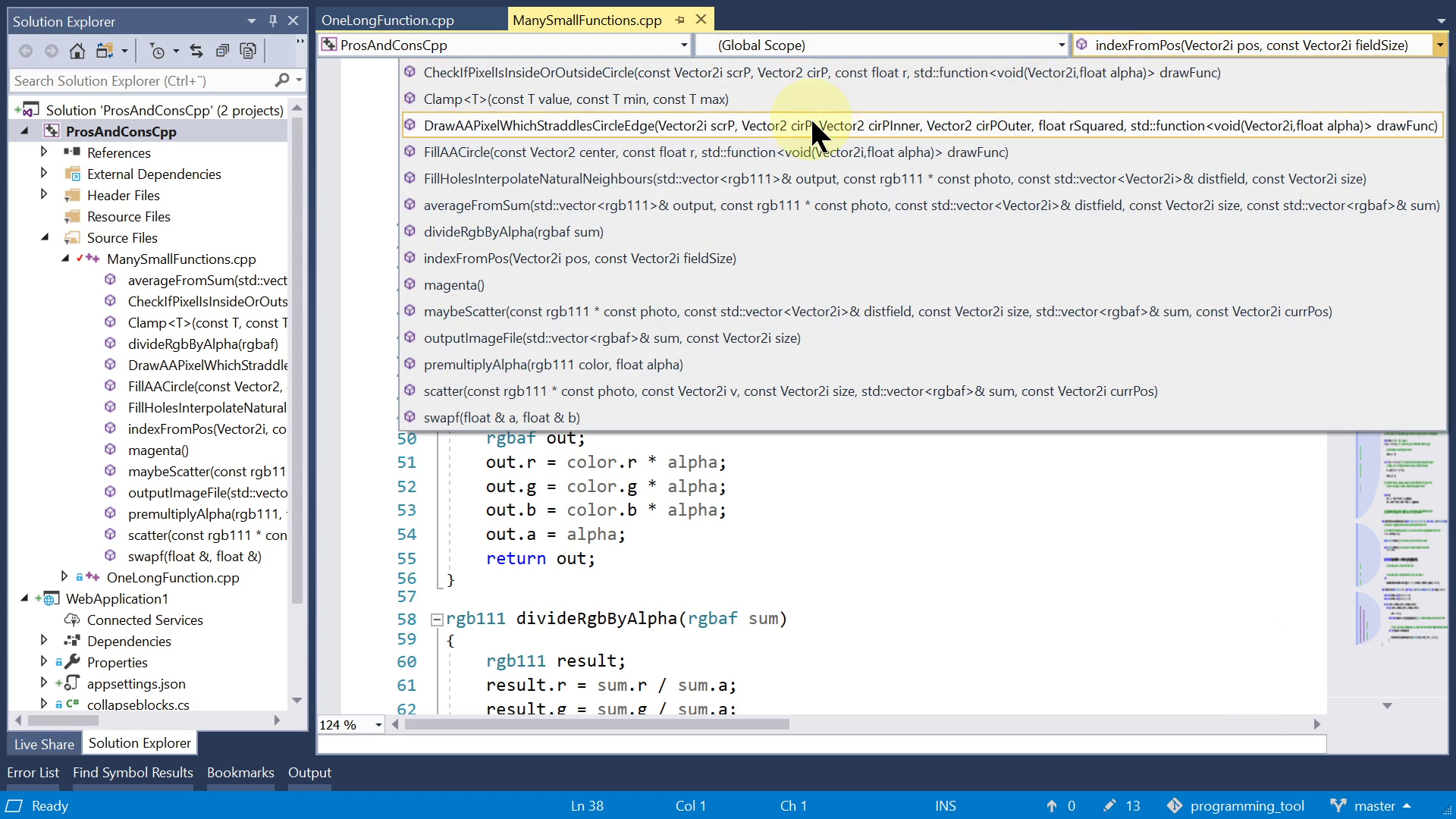
Ok, the first advantage of using many small functions: IDE can find by name. In an IDE like Visual Studio, you can use this menu to jump to a function. If you instead have just one single long function, this menu is useless.
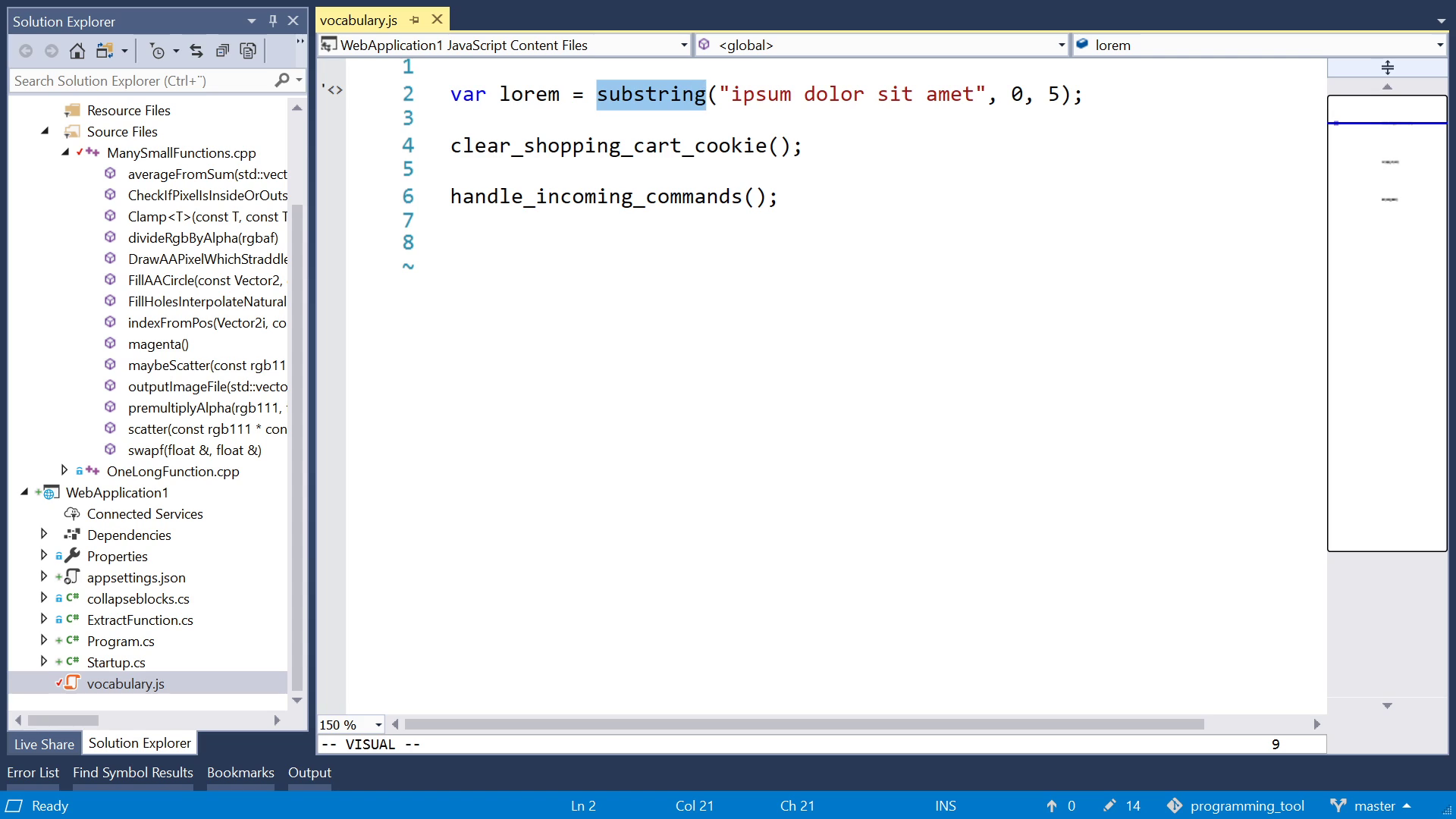
If you follow the classic advice and split up your code into many small functions, it helps hide irrelevant details when you're reading. While seeing all details would just distract from the big picture and waste your time. For example, when you see a call to the function "substring" which is common in many programming languages, you probably already know what that function does. "substring" has become a part of your vocabulary. Code which uses a rich vocabulary has higher information density - it can explain more in fewer lines, if you understand the vocabulary. This advantage is less clear-cut with functions which are not already in your vocabulary. That's why we need good names. If a function is named "clear_shopping_cart_cookie", you can draw on your previous experience with online shopping and make a qualified guess as to what the function does, without reading the implementation. But if the name is something vague like "handle_incoming_commands", you can't be sure, the details might be important to you, or not. Also, "important" is contextual - depends on what you're working on at the moment.
Another kind of distraction comes from having long bodies that obscure control flow because ancestors are far off-screen. So you don't see which if, else or while you are inside.
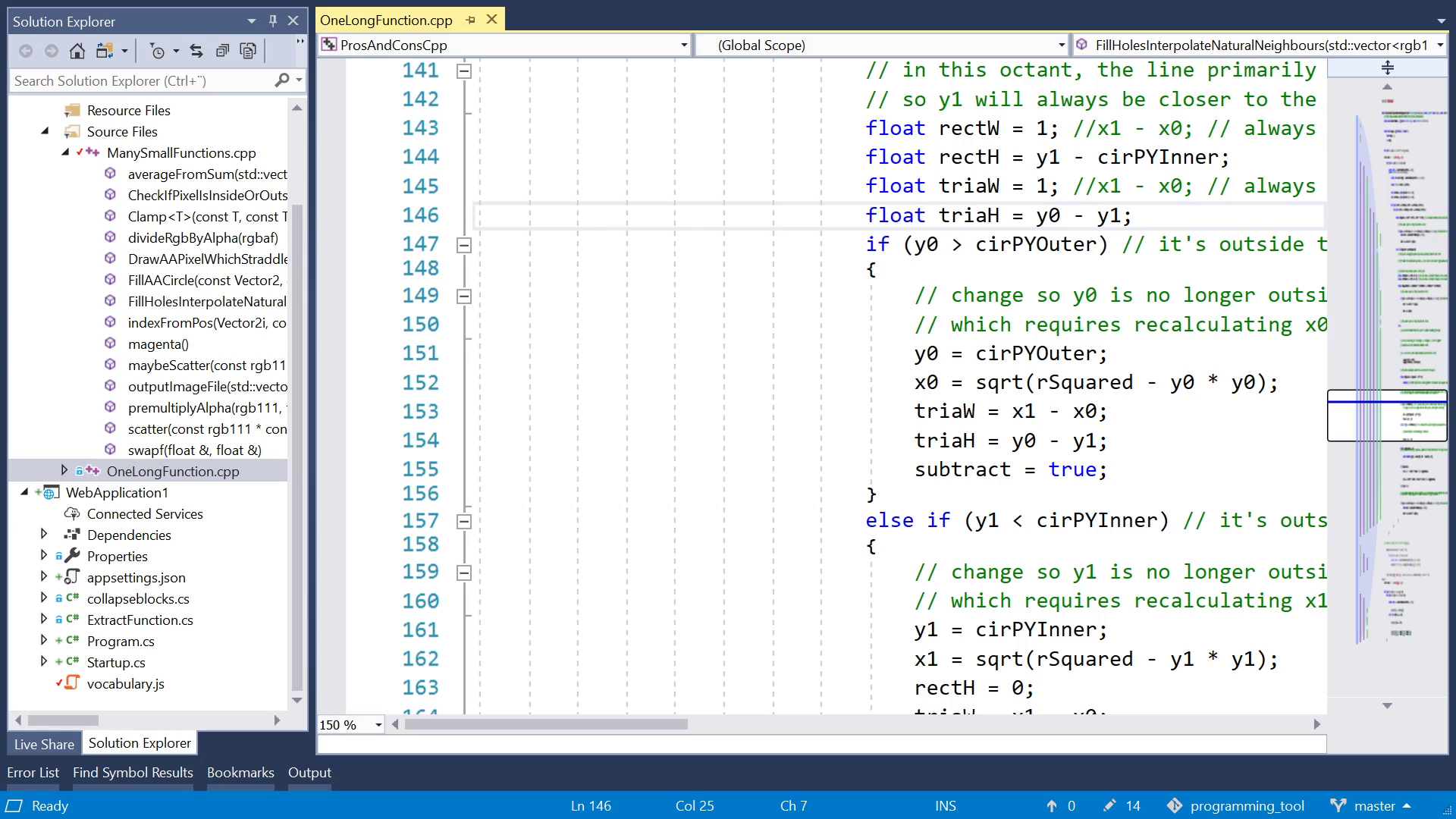
Next, indentation depth. If you let functions grow long, you may end up with a "for", containing another for, containing an if, with another two fors, and so on. Each one adds one level of indentation, so pretty soon the left half of your screen is just whitespace, and more and more lines start to become too wide for your screen. That's a waste of space. Whereas, if you start a new function, you get a fresh start at the left edge.
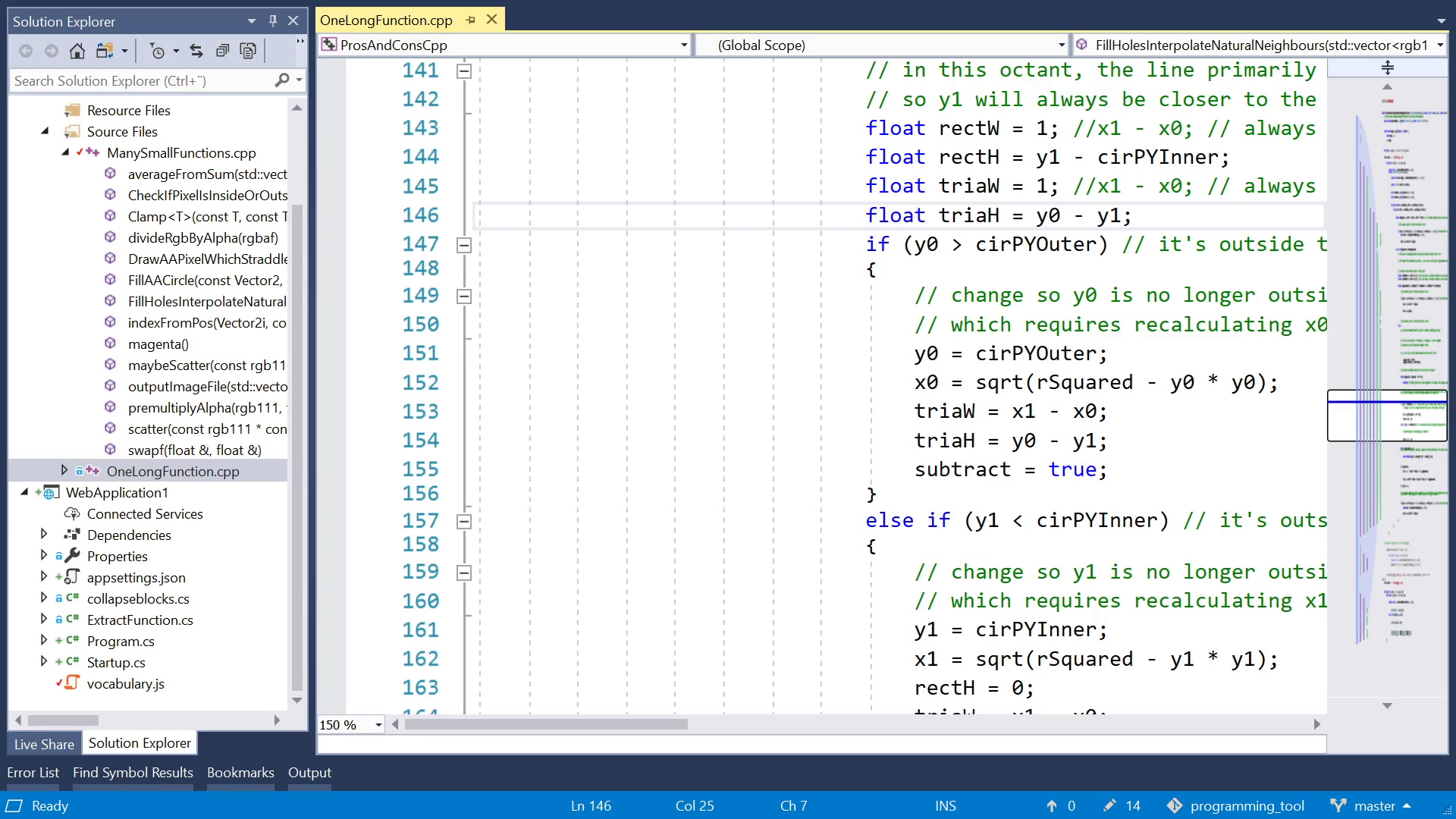
Next, variables in scope. With a long function, you tend to also get a large number of variables. But any given piece of that function probably only reads or writes a small number of variables. But you can't quickly tell which ones, at a glance. So the data flow is less obvious.
Next, the disadvantages of small functions.
Editing is often scary. Because you don't know if your edit is going to work for all of the callers. Maybe one caller relied on the old behaviour and will now break. So you search your whole codebase to find all the call sites, and read them one by one. Maybe you even have to look one or two steps further out. And after your edit, you run tests that cover every call site. This is time-consuming and tedious, so if you're in a hurry, you might get sloppy, and cause a bug. Happens all the time. With longer functions, a larger proportion of your edits tend to happen in places that are less scary, where the surrounding context is right in front of you.
If you're looking for a bug, the bug might be in any function, so you can't know which details are irrelevant. Everyone is a suspect! So you want to follow the whole linear sequence of execution, but if you have a lot of small functions, that sequence isn't linear at all in the source code, which means you jump in and out of a lot of functions, and try to remember what you saw before the jump, and reconstruct the linear sequence in your mind. That can be quite hard. Personally, of all the points in the list, this one is the biggest for me. When I have to jump around too much, I sometimes lose track and get confused.
Ok, I think we've heard enough pros and cons. I could have included more, but I skipped them to save time. I hope you found my list to be fair, anyway.
To summarize, I'm gonna steal two terms coined in this nice blog post: local and global readability. Having many small functions gives you good local readability. "What does this function do?" You get these bite-sized, easily digestible chunks, but often at the cost of worse global readability. "What do these 10 functions do together?"
So the dilemma exists because our desires are contradictory. Sometimes we want irrelevant details hidden, and to think in higher-level concepts like "substring" or "clear_shopping_cart_cookie". Another time, those details are suddenly relevant and we wish they were right in front of us. The only way to achieve one of them is to refactor the code and thus lose the other. We can't solve this problem on a code level. But we could solve it on a tooling level! So let's see how current editors deal with it.
Imagine you're in an editor, and you see a call to a function, and you wonder "when this code is executed, what's gonna happen next?". In a really simple plain text editor, you would search for the function by name.
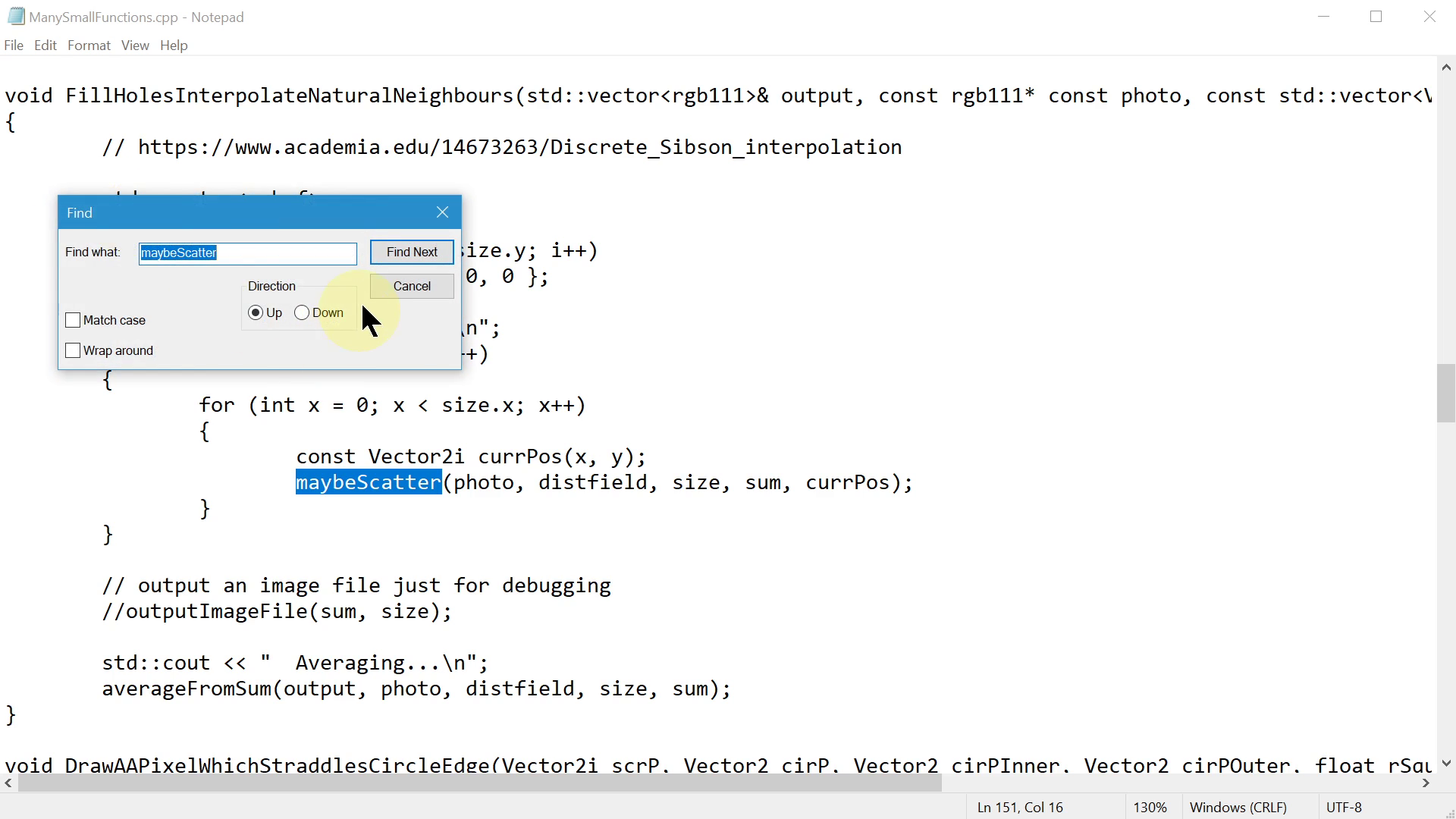
In a slightly more advanced editor, for example here in Sublime Text, I can click in this menu, or use a keyboard shortcut, to "Jump to Definition". Then I can hit the "back" button to go back to the call site.
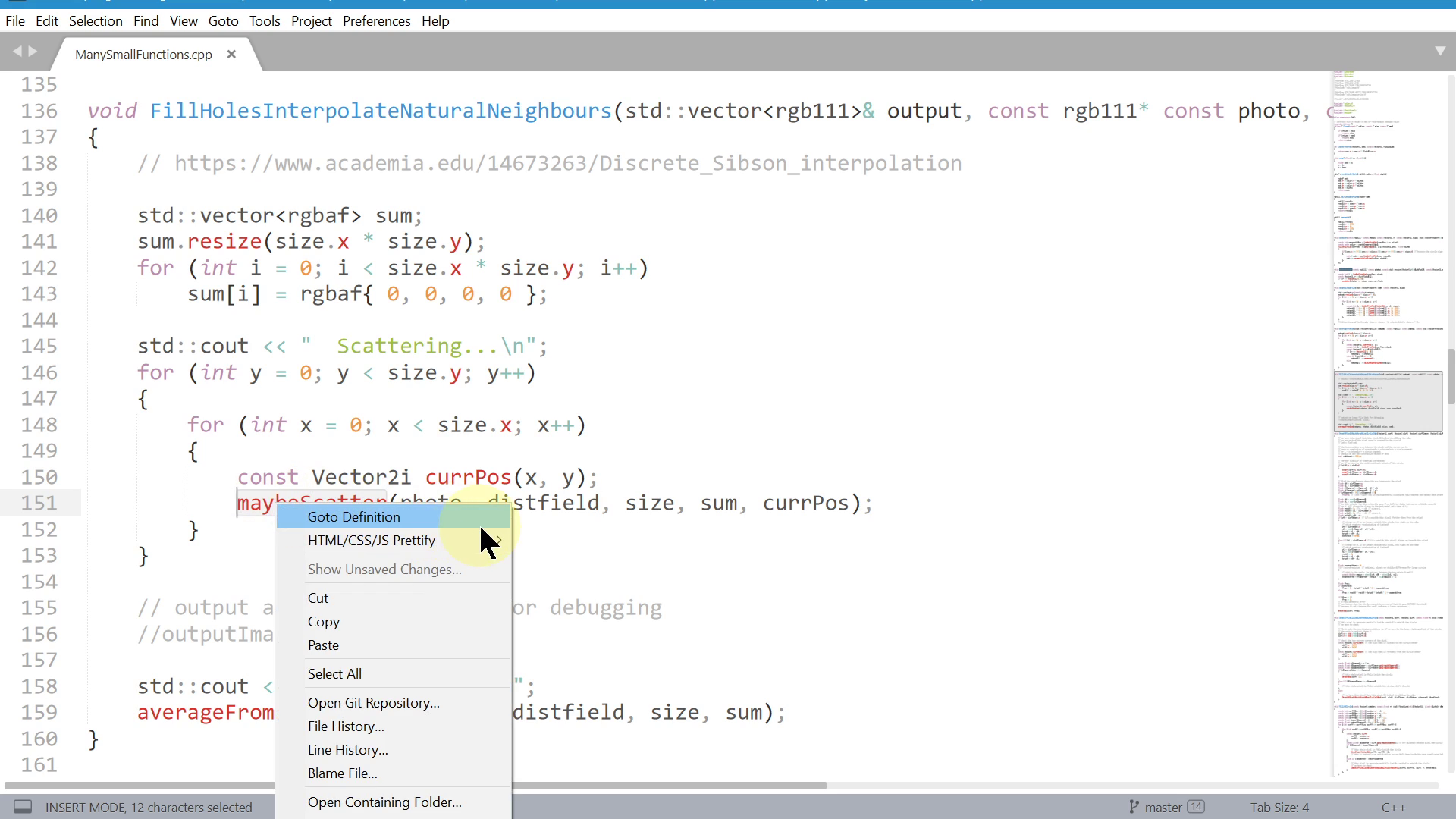
That's nice, but I only see one thing at a time, so I have to remember, I have to mentally track things between the call site and the function definition. Like I said before, when I have to jump around a lot, I lose track and forget things. It would be nicer to see both things on screen at the same time.
One popular trick is to open two panels side by side in the editor.
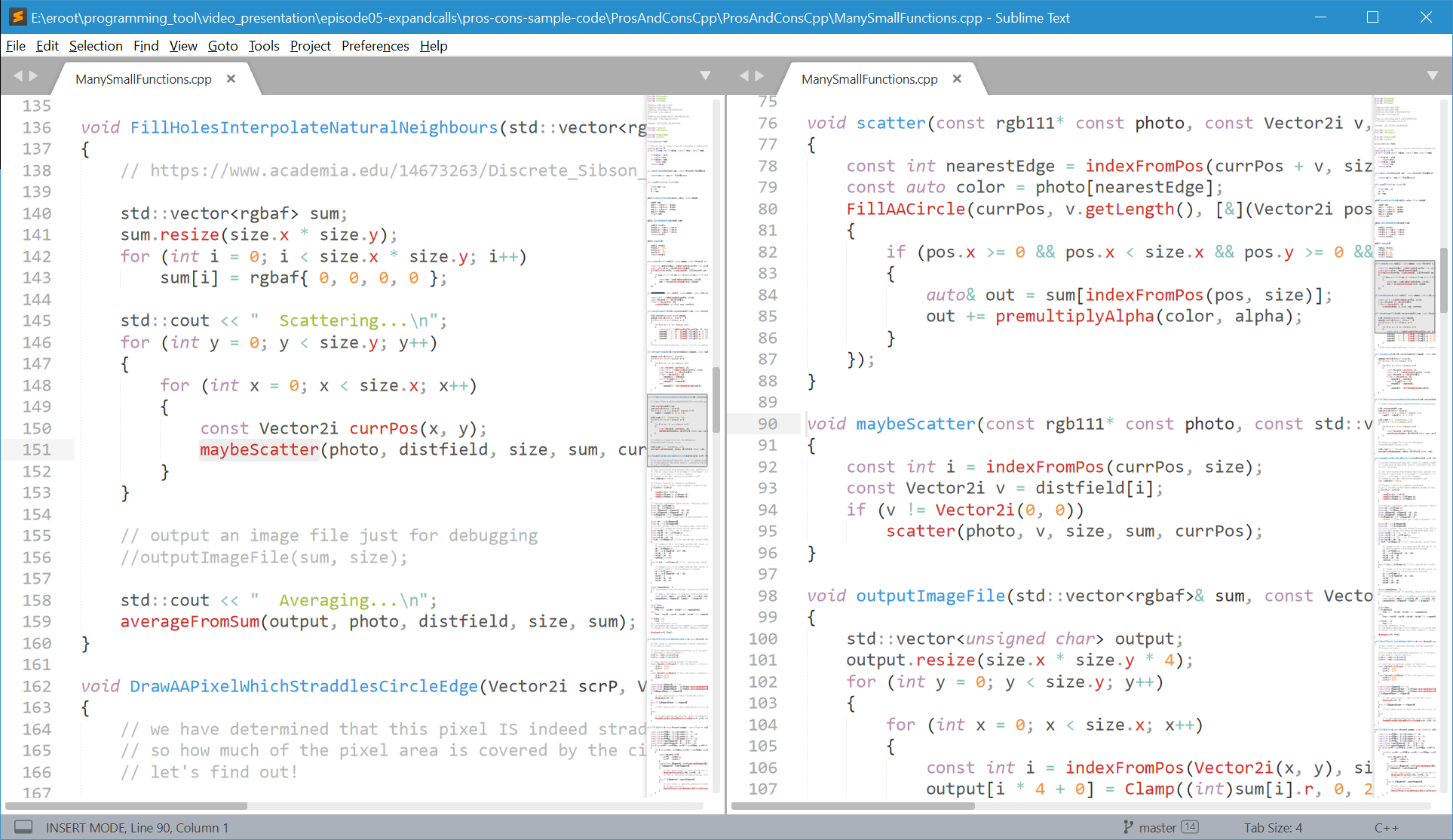
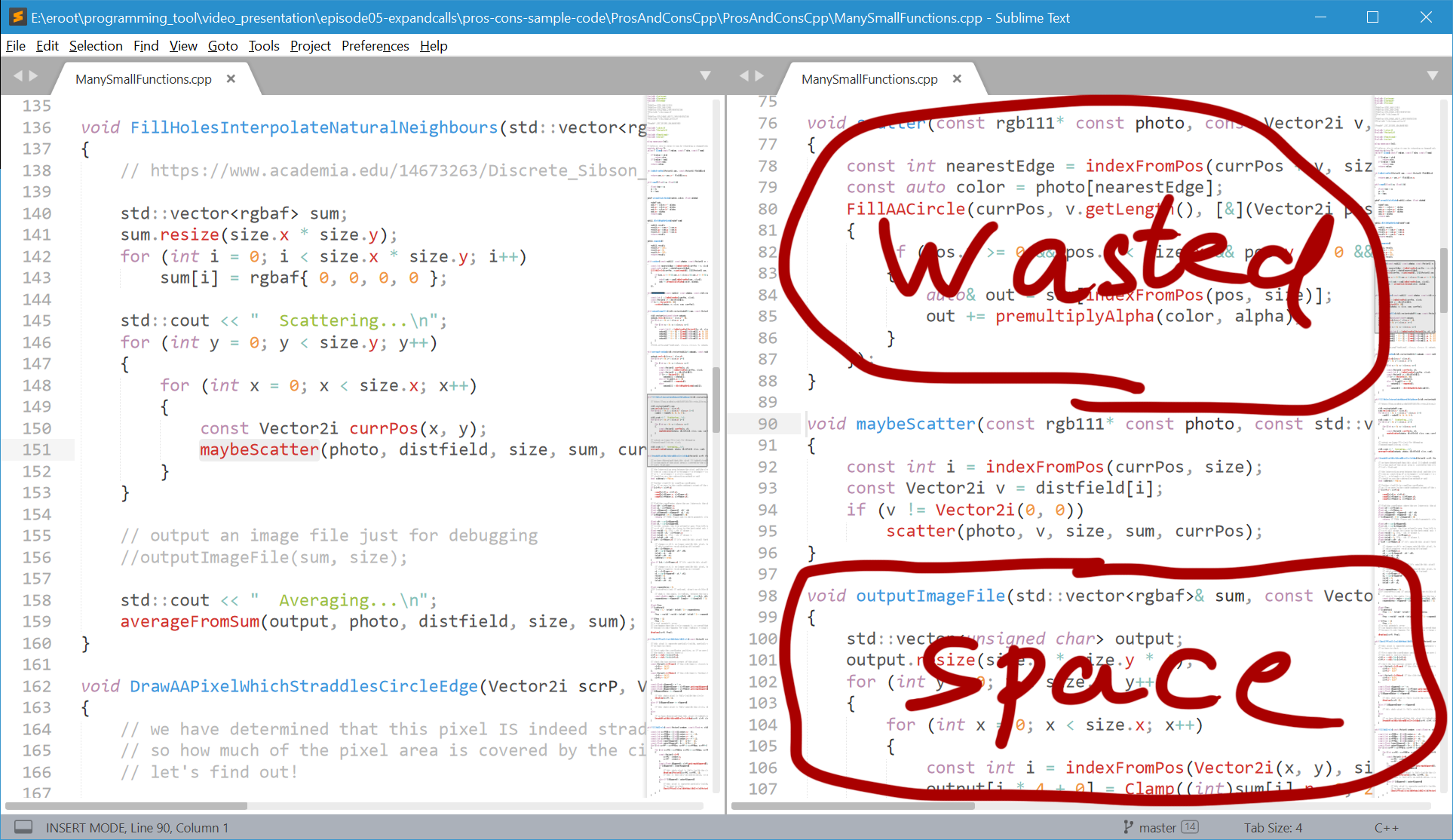
So here on the left, we look at the call site, and here on the right, we can read the called function. That's nice but I have a few complaints. Setting up this layout requires too many clicks, it's too manual, and therefore I don't do it often. Also, above and below the function definition on the right, we're wasting space that could maybe be used for something.
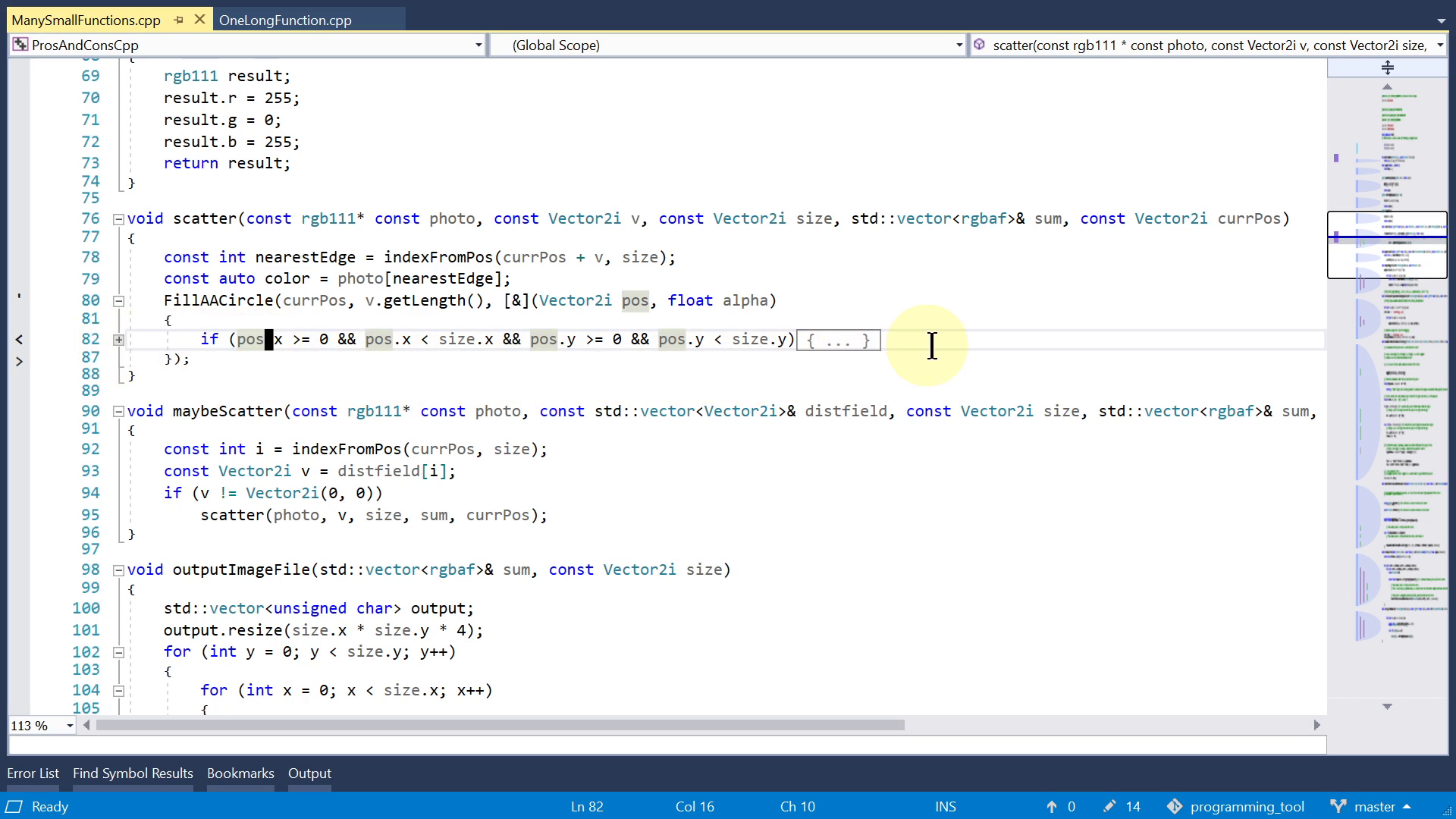
Another way to see both things at the same time is here in Visual Studio. It has this feature called "Peek Definition", which is a step in the right direction but it doesn't go far enough to be really useful. It opens a small window. If the function is long, the window just shows you a small part and you have to scroll. Not very nice. And you can even scroll outside the function in question. For no good reason.

Functions aren't the only way to hide details. Every block, like the bodies of if statements and loops, have these small toggle icons on the left edge. When I collapse this block, by clicking the little icon or pressing a keyboard shortcut, it becomes a single line that just says {...}. This is nice, and I use it sometimes. But I think it hides too much information. "..." gives us no information about the block. Umm, let's come back to that later.
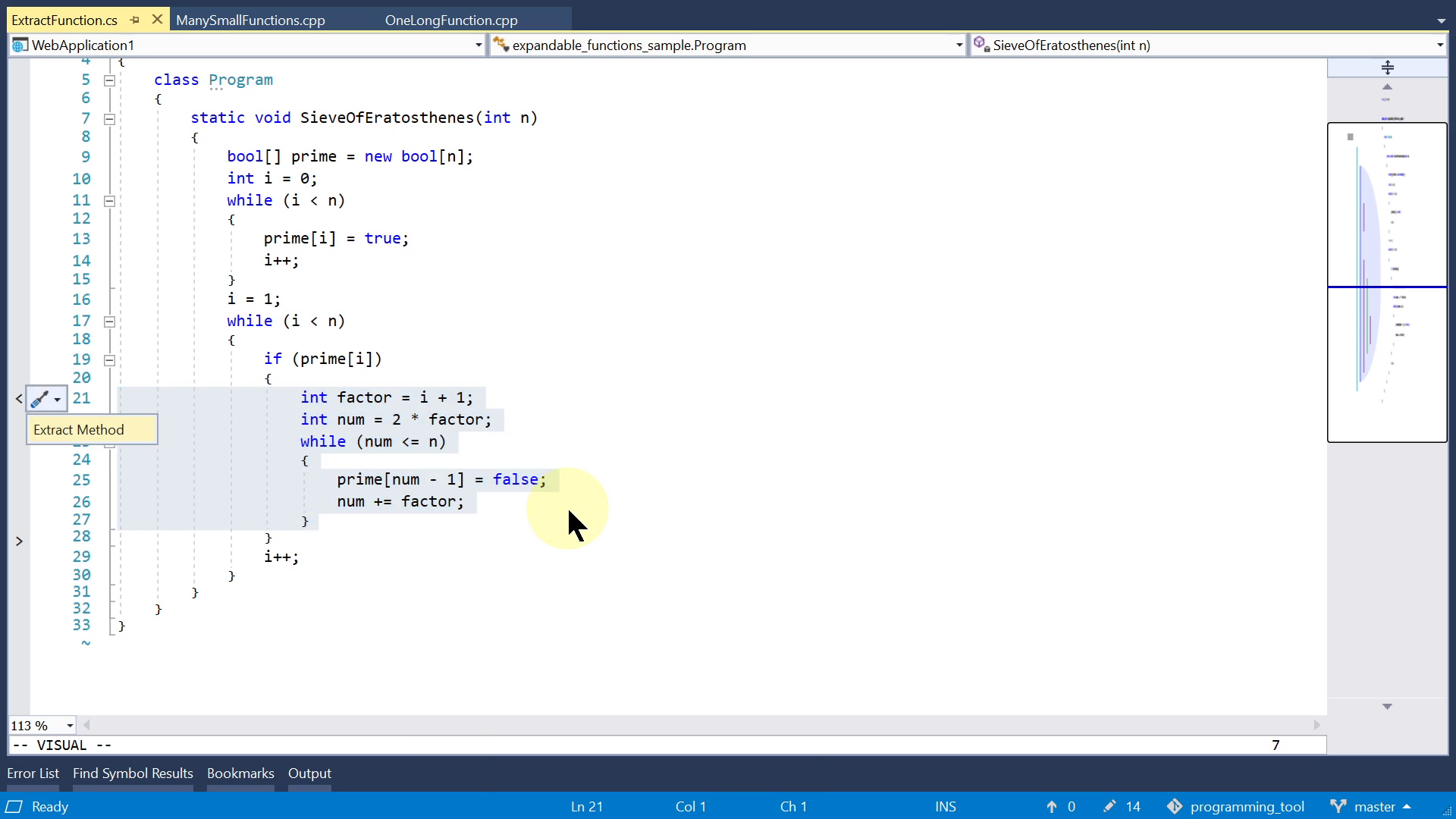
All the above features are about reading code, so let's also talk about a feature that helps you edit code. When you decide that a piece of code deserves to become a separate function, maybe you don't have to do it manually. Some editors have this feature called "Extract Function", which takes the selected lines and moves them to a separate function and automatically sets up the arguments and return values.
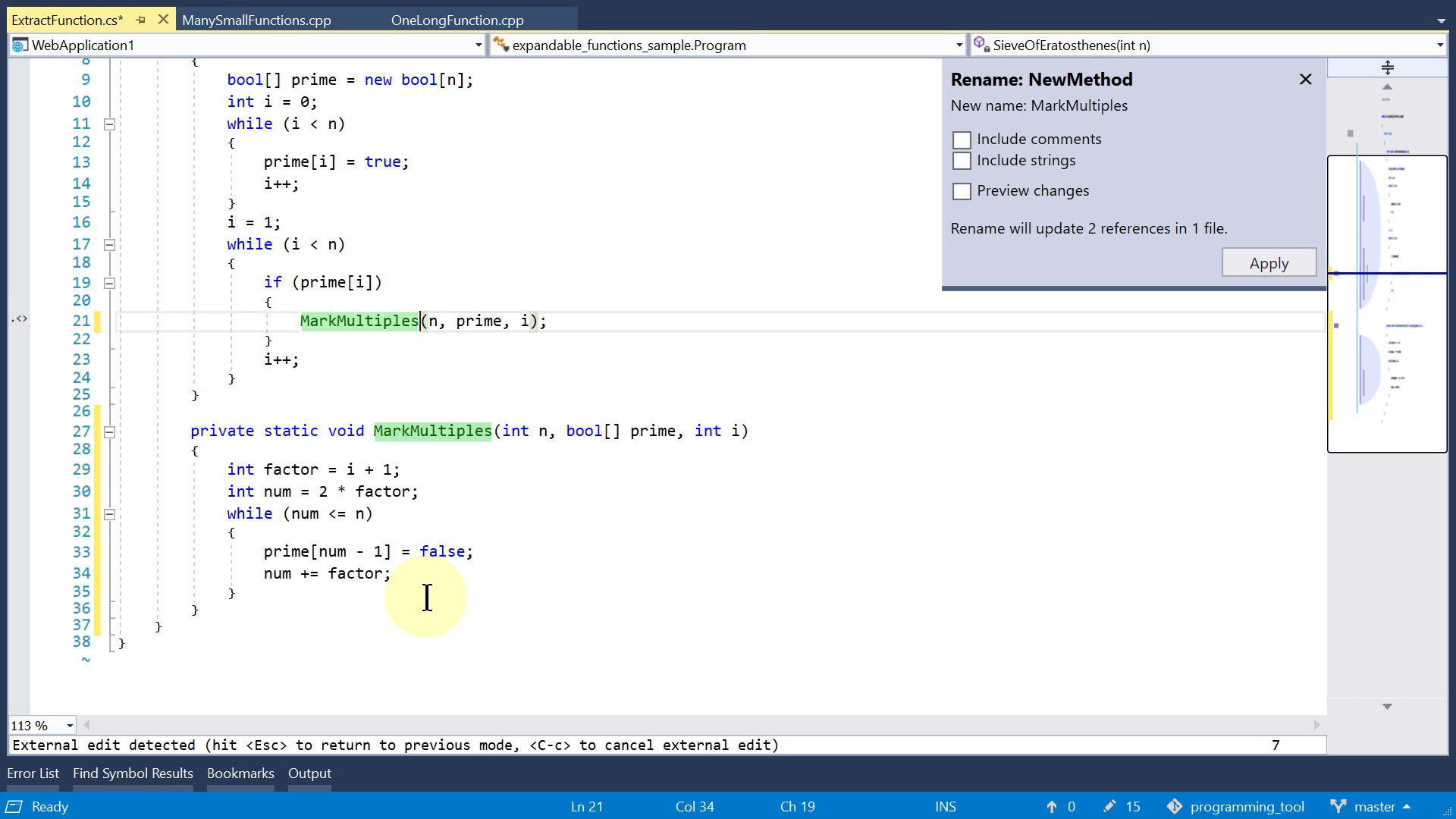
If you later change your mind and want to go back, most editors can't help you, but in the JetBrains IntelliJ family of editors there is also an "Inline" feature which performs the reverse of the "Extract Function".
Now let's look at my tool ideas. I've made a prototype in the browser.
Using a left & right pane for caller and callee is common enough that it's worth automating. It could look like this.
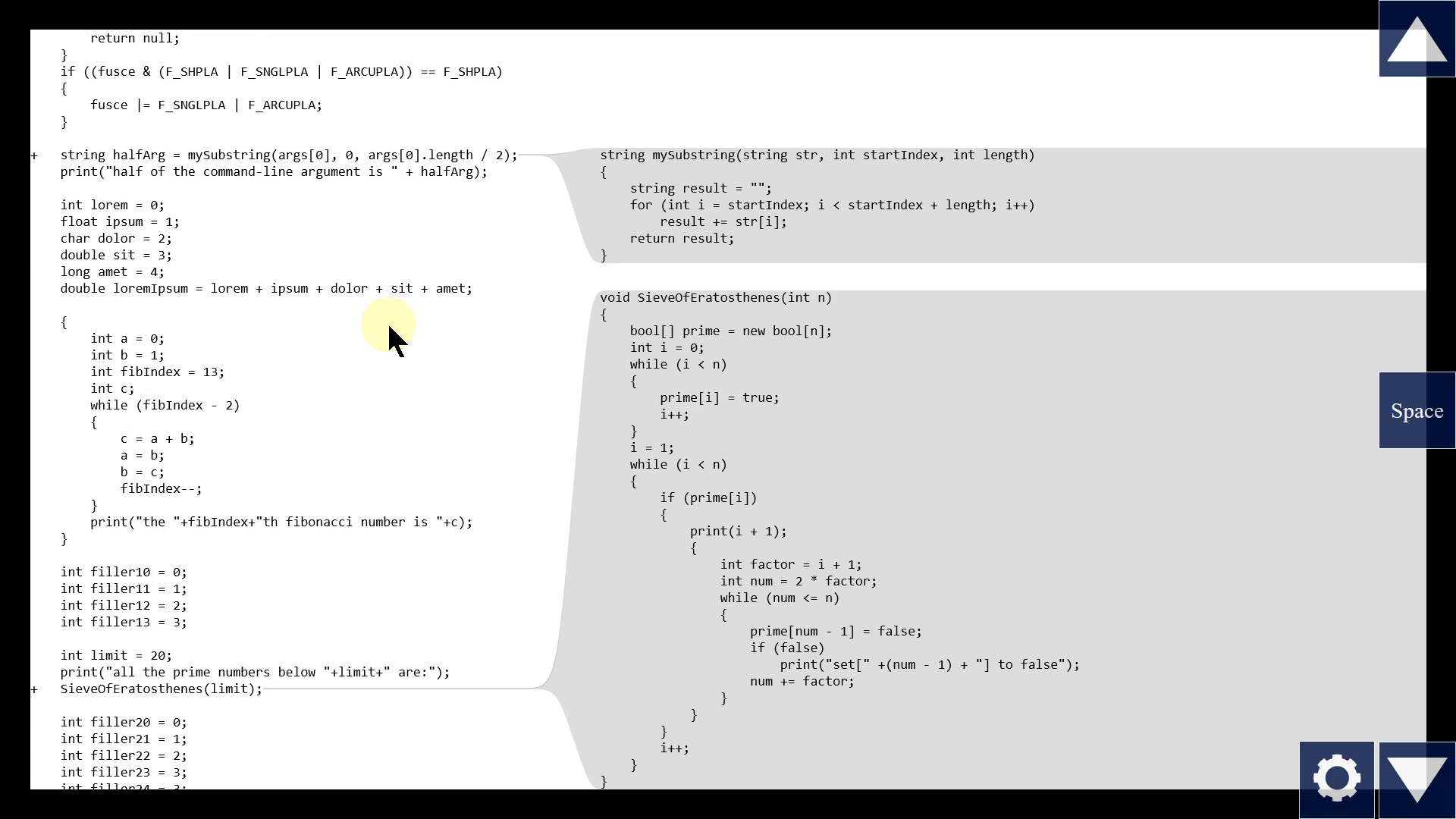
The tool finds all calls on screen on the left side, and shows those functions on the right side. So when we scroll on the left side, different calls come into view, so the right side automatically changes.
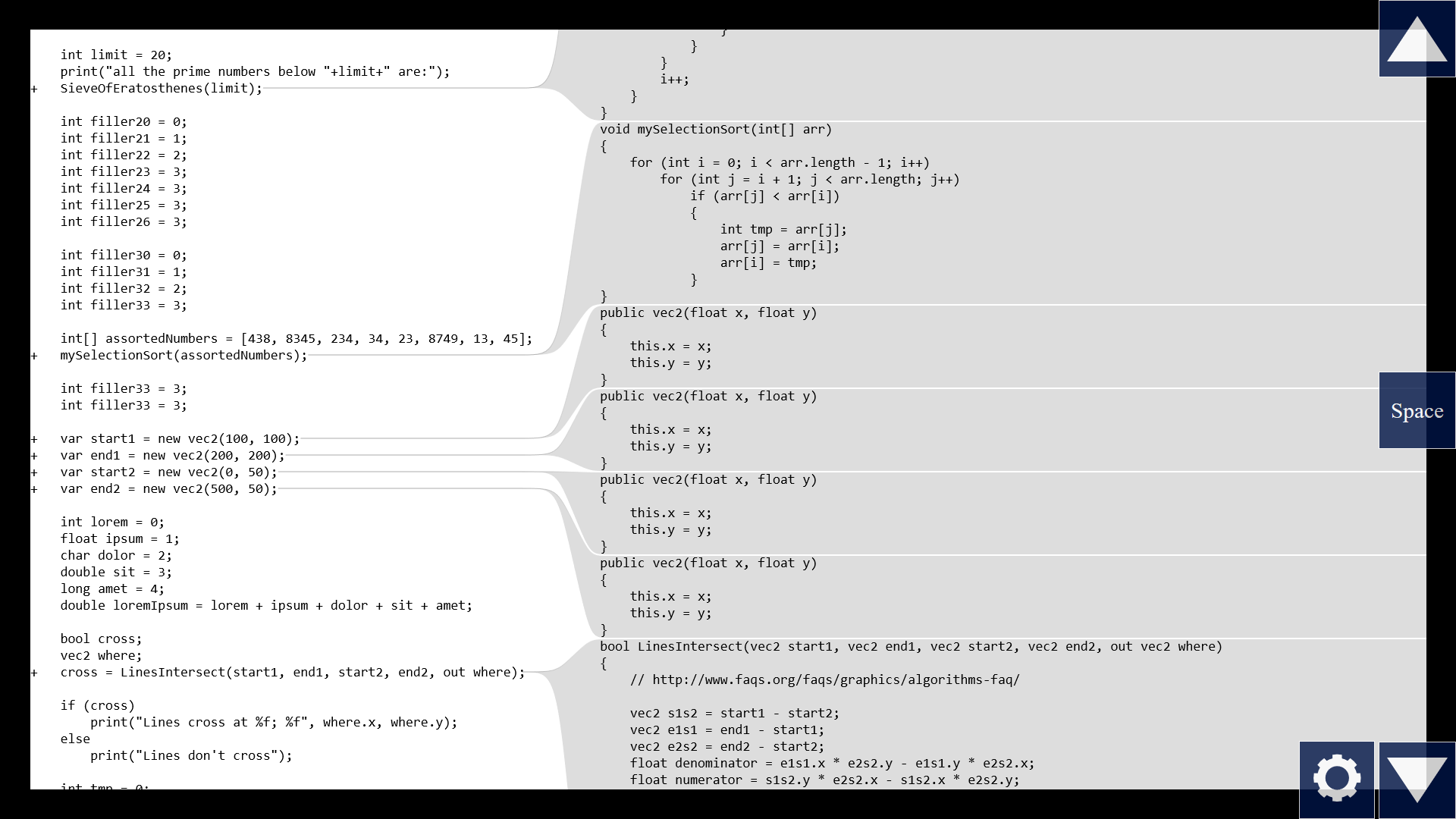
But what happens if there are a lot of calls on the left? We can't fit all of the function bodies on the right side at full font size.
Umm, we can save some space if there are several calls to the same function next to each other. Only show that function once on the right side.

And let's scale the font size like in my Episode 2.
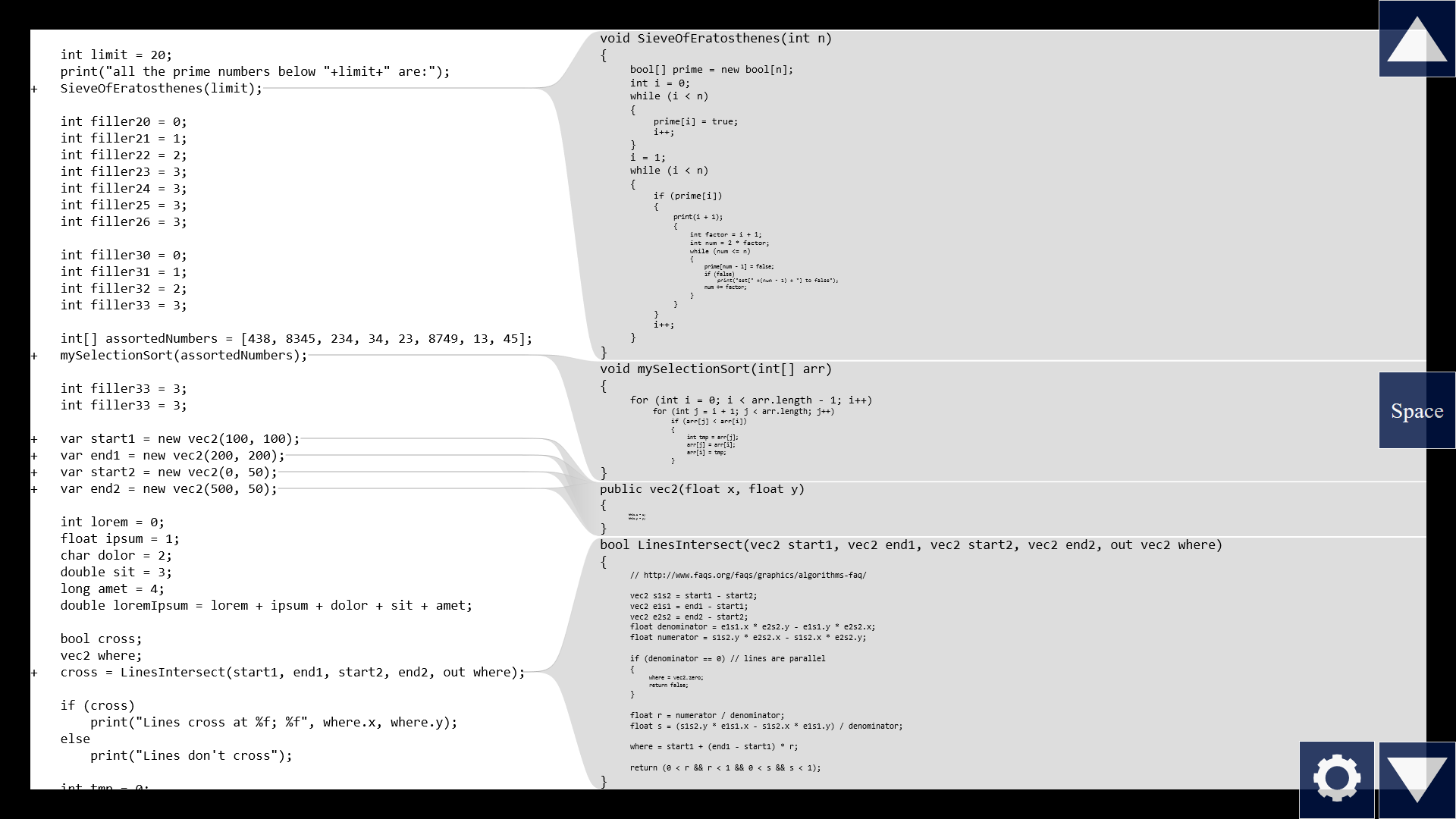
This way we get an overview, but now the bodies might be too small to read. So if there's a particular function that we're interested in, we can put the caret at the call site and press space, or just click this plus icon, to enlarge that particular function to full font size on the right side.
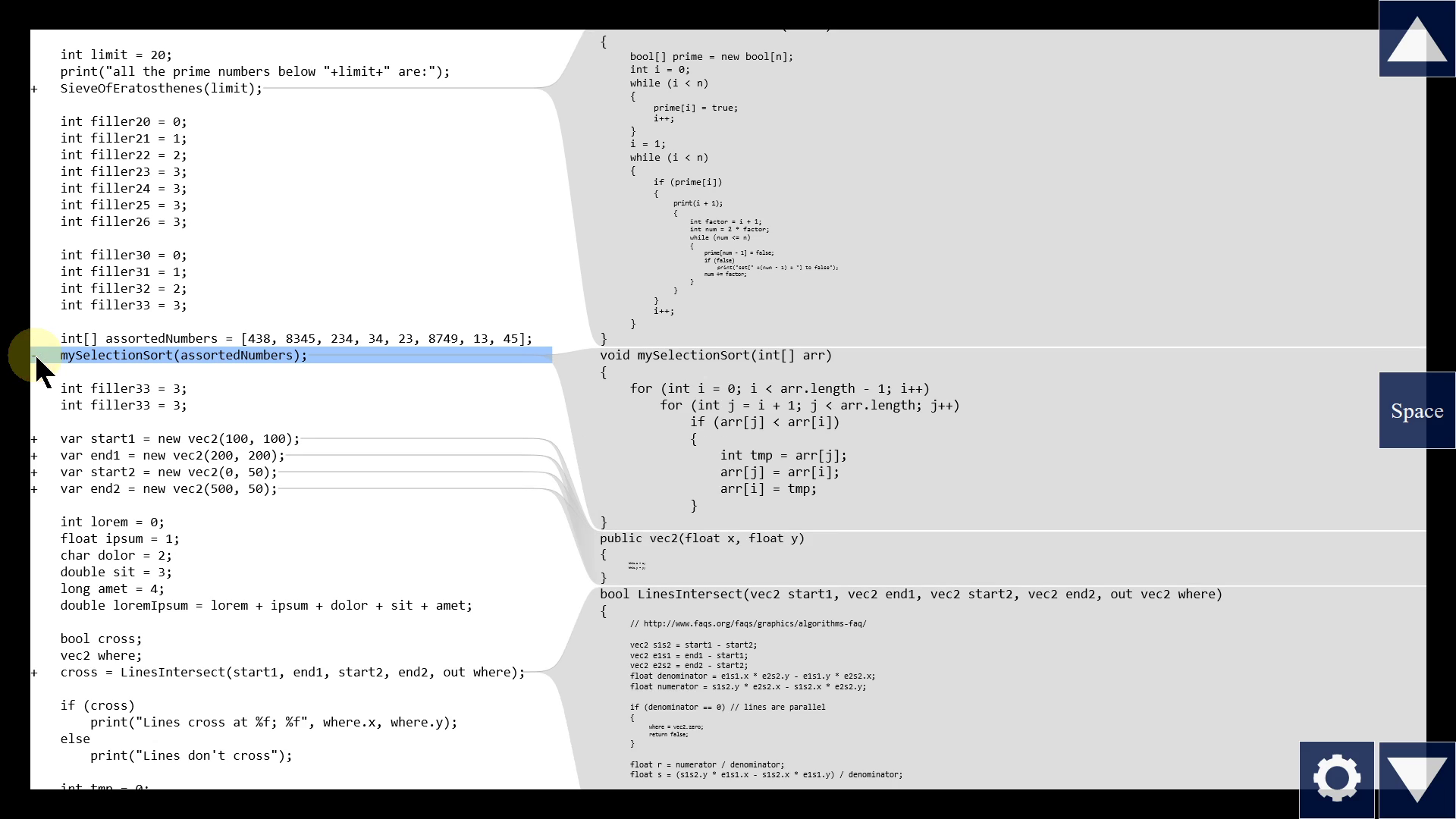
Back to the collapsable blocks in Visual Studio. Again, "..." gives us no information. What we want is some kind of short summary of a block. It could be similar to a function signature! Because I think we care about variables that cross the block boundary. What does that mean? Well, there can be variables from above a block that are read inside the block - they correspond to normal function arguments, so we could call them "in". Other variables from the outside can be overwritten inside the block - they correspond to return values, or "out" parameters in C#. And some are both read and written inside the block - they correspond to passing arguments by reference. So instead of "...", an editor could automatically show me a list of all these variables - out, ref, in.

This is very similar to the "Extract Function" feature, but instead of actually extracting, this tool just visualizes what the signature would be.
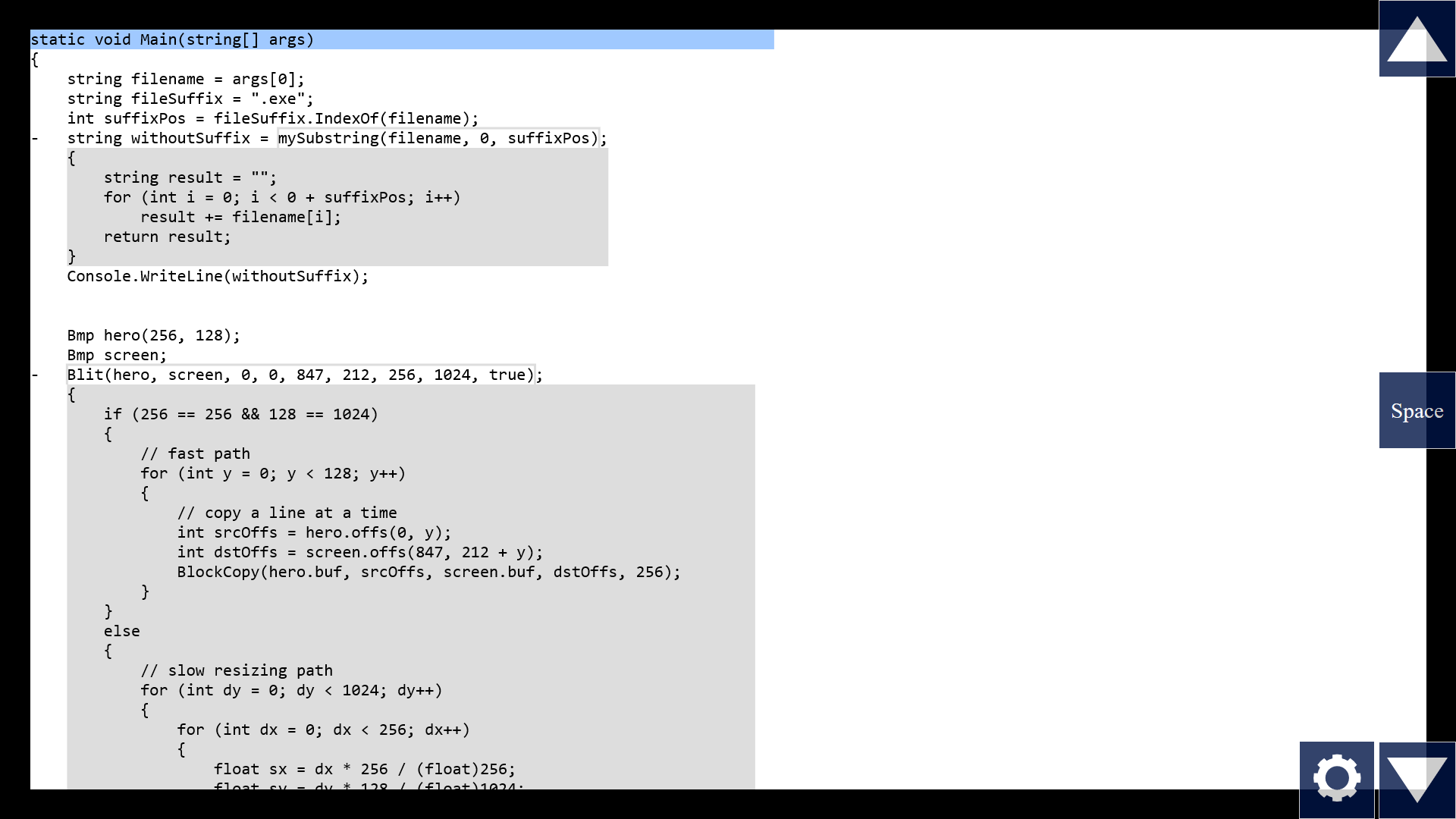
Now, if we can collapse blocks, we should also be able to expand function calls. It's kind of the same thing in reverse. Seems kinda obvious, right? We can do better than "Peek Definition" in Visual Studio. The first step is to just inline the whole function when I click the toggle.
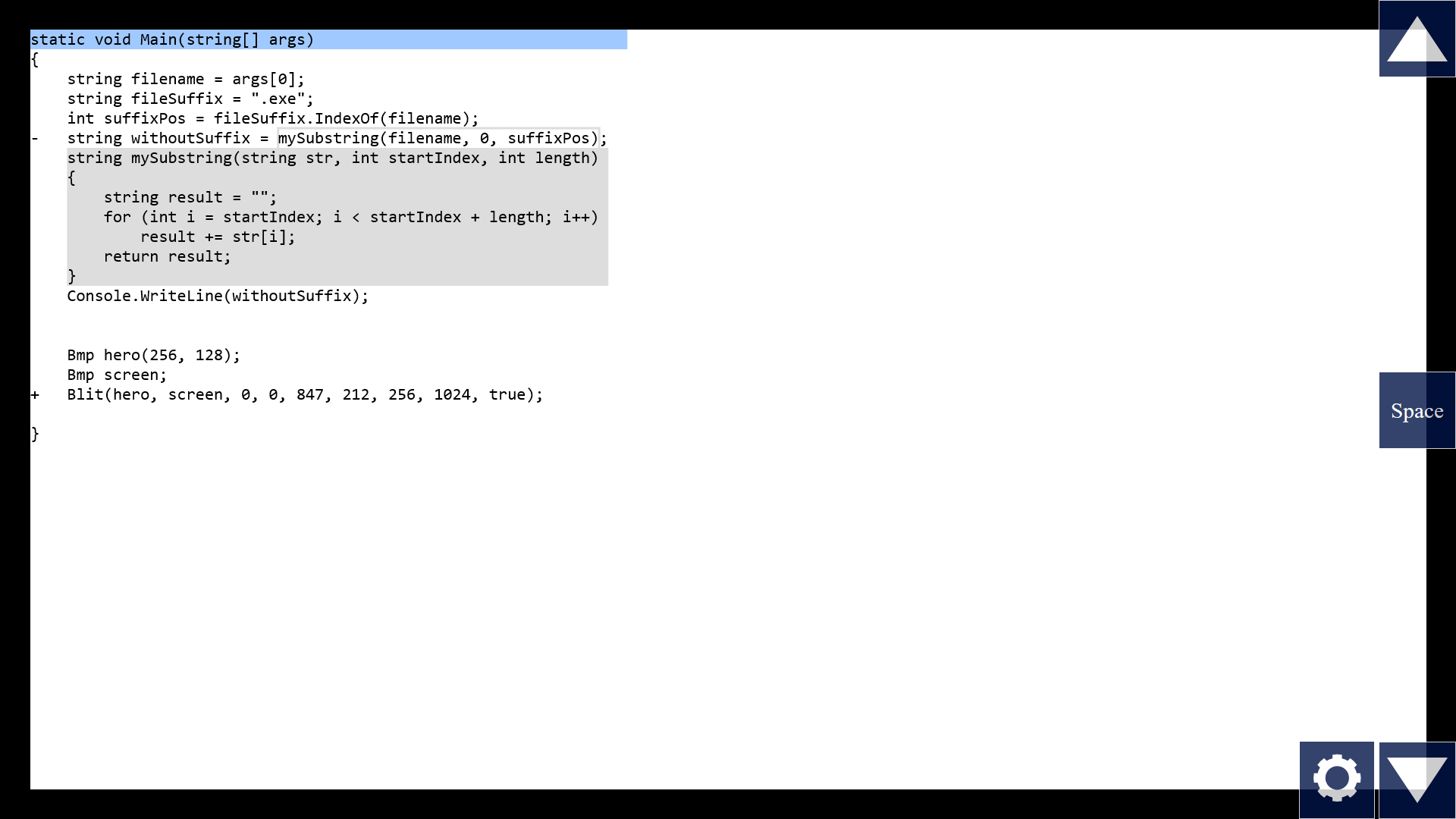
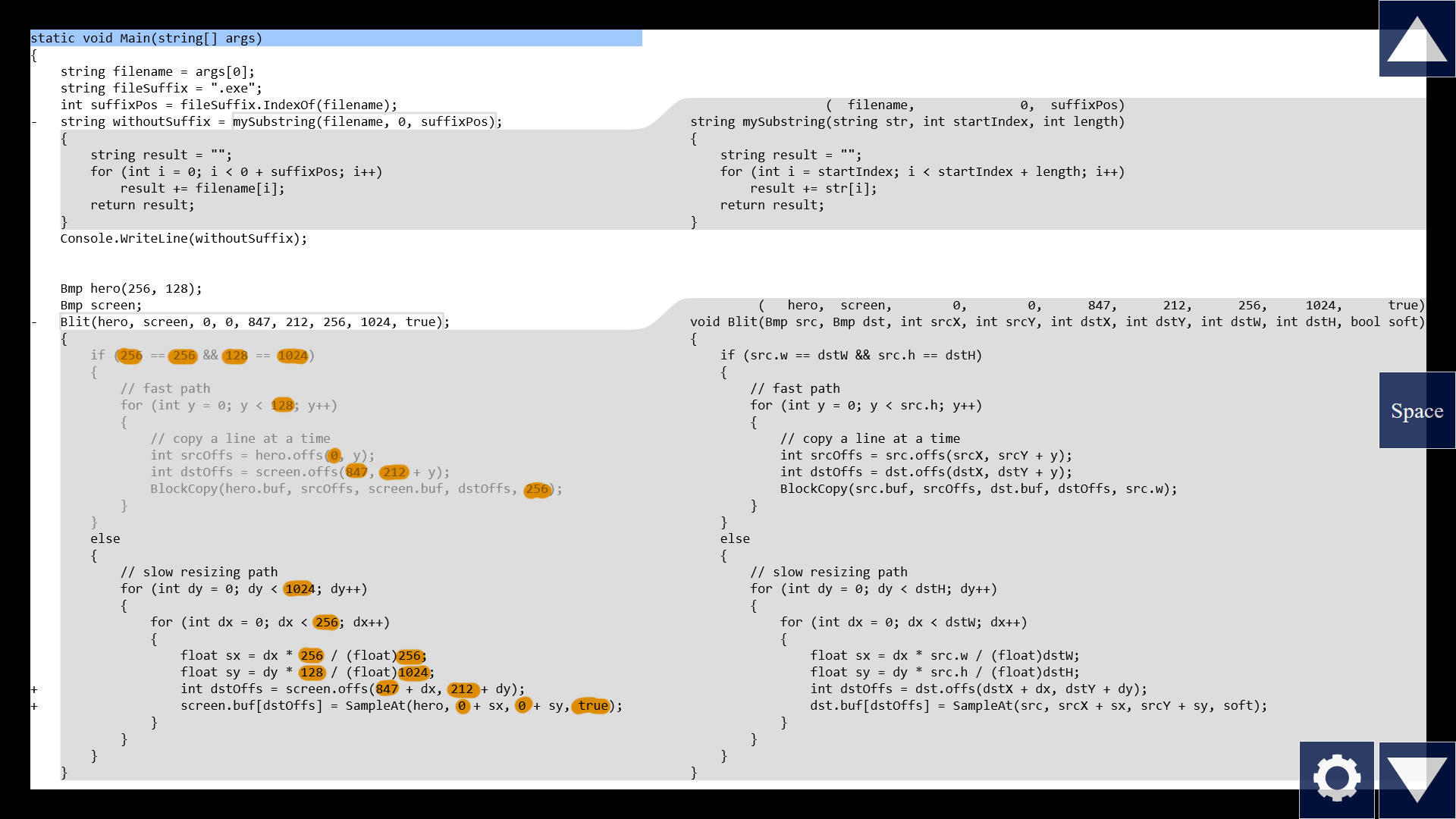
Note that when we call a function, there's a remapping of names from the outside to the inside. I mean, I could pass in the argument "suffixPos", and inside the function, the corresponding parameter is called "length". And for functions that take lots of parameters, it's easy to get them mixed up. Which one maps to which one? It's not clear, we might have to count from the left, like "one two three four..." But what if the tool horizontally aligns the parameters with each other?
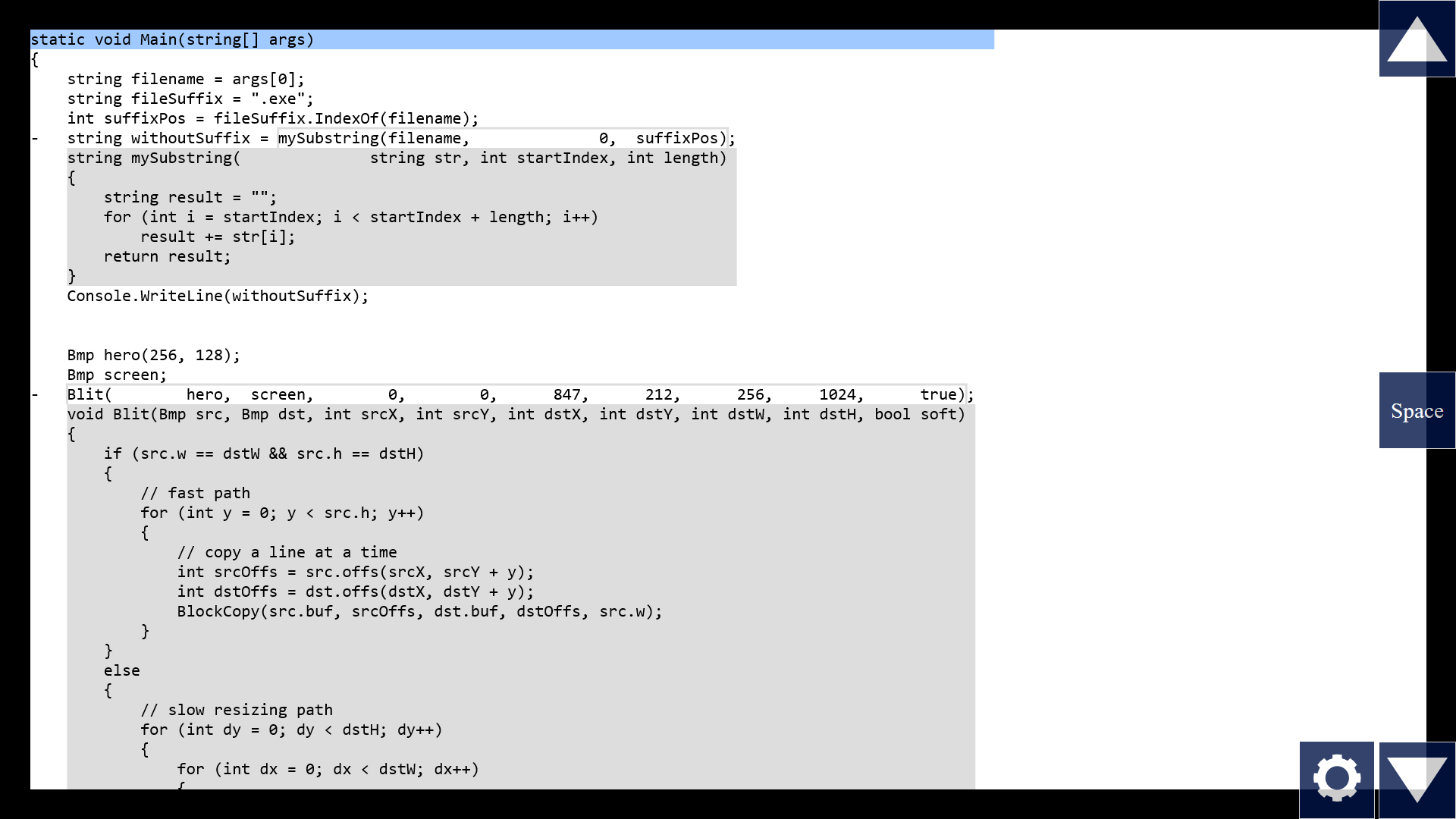
Now I don't have to guess. Takes up a bit more horizontal space, but my 4k screens should be good for something, right?
But we can do even more than that! If the tool can help us see the mapping more clearly, couldn't it instead just do the mapping for us? Like, if we were to manually inline this substring function, we would simply replace all instances of "length" with "suffixPos".
Like I showed before, the required intelligence for automatic inlining already exists in some editors. They just need to visualize the result of inlining without actually permanently editing the text file.
But we can do even more than that! Note that some things we pass in are not variables but hardcoded constants, like the number "0" or the flag "true". They're known at compile time. So they're available for static analysis here in the tool. We could show, right now, the consequences of those values. For example, this if-condition becomes a constant expression which evaluates to false. So the tool can know that this branch will never be taken, from this call site. So it can show the whole branch grayed out. This might in turn cause other things to collapse to constants, too, in a chain reaction.
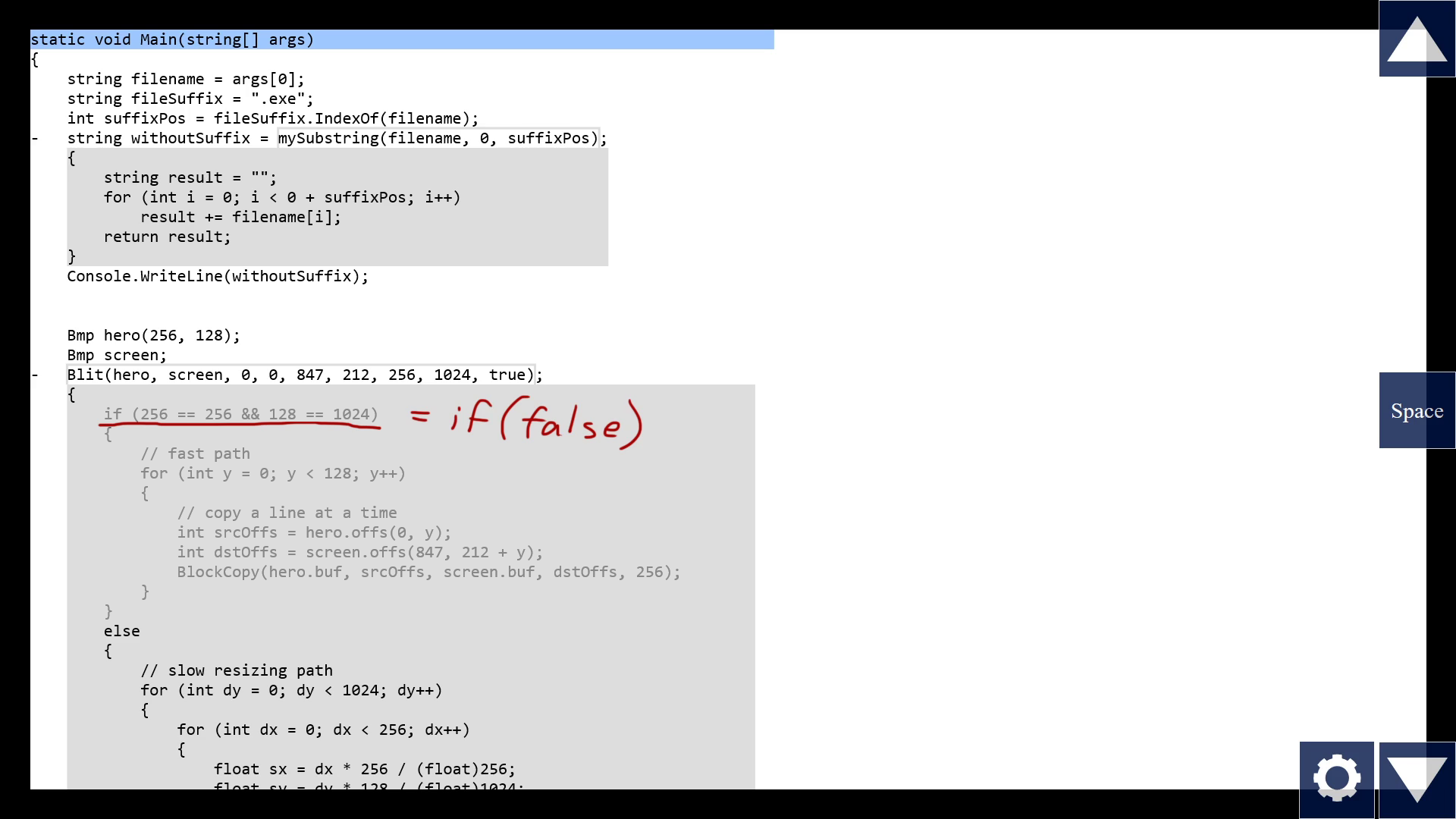
If you've heard about partial function application, this is very similar. Let the computer do what computers do well, and show it, so we don't have to play computer in our mind.
But now, this "partially evaluated" view with "substitution" might look quite different from the original function code, so maybe we want some help understanding how one maps to the other. We could show them side by side! Let's combine this inline expansion with the functions in the right pane that I showed before.
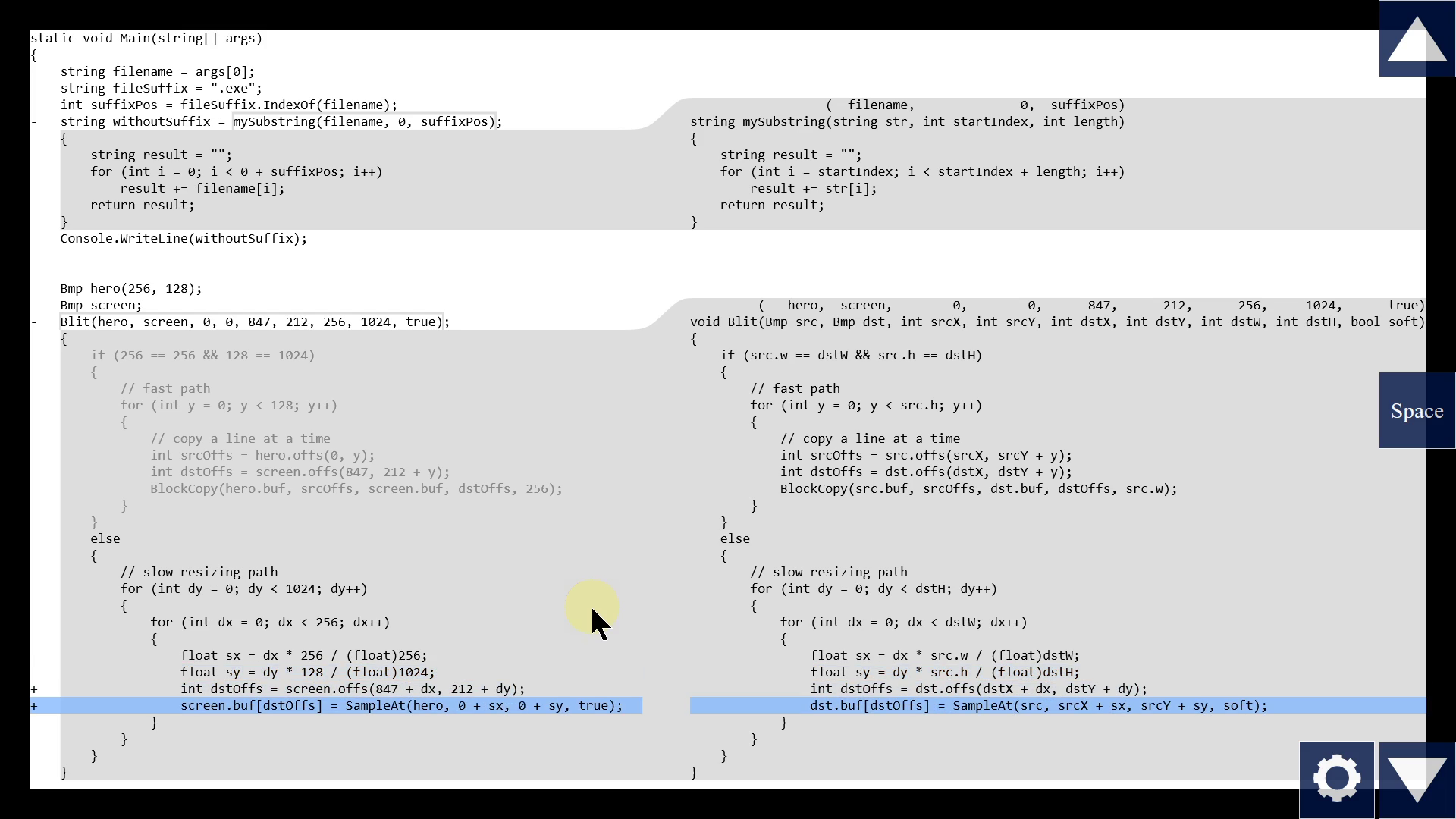
There we go. We see the original function body on the right, and our specific instance on the left, and we can easily compare line by line.
What if the original function itself contains a function call? Of course, we should be able to expand that too, recursively.
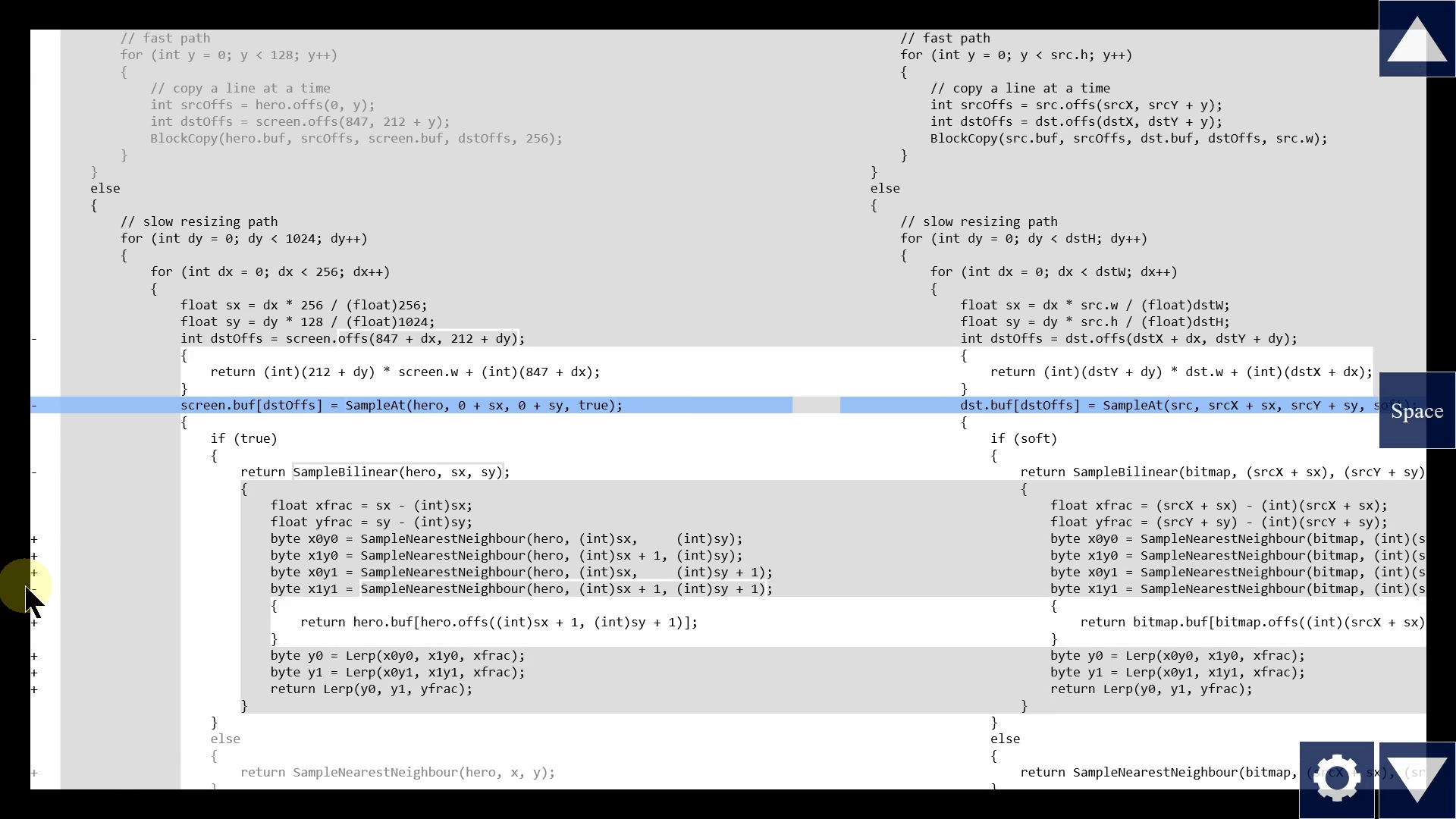
That's all I have prototyped so far. You can try it yourself. Link in the video description. And let me know if you think it would help you in your programming.
So, what's still missing?
I wanted to have animation too, but I skipped it to save development time. You'll have to imagine that the finished tool would support it. I think animations make it easier for the eye to understand all this expanding and collapsing. But they should be really quick, to not waste our time, and crucially they must not block input. We must be able to input with mouse and keyboard at full speed, even if an animation is running.
There are many situations this prototype doesn't handle yet, help me think about these open design problems:
Should we be able to edit the code inside this "partially evaluated" view on the left? My prototype doesn't support editing, so we have to imagine it. Editing some things in the inlined view wouldn't make any sense. For example, this number "256" here, it comes from the argument we passed in at the call site, so what would it even mean to edit it here to say "300" instead?
But other edits totally make sense, for example adding a line that prints "hello world". So we could have an editor where some tokens are locked and can't be edited, while others can. Or that might feel confusing or annoying. In that case, the simpler design might be to only allow editing in the original function instead, on the right side. So when we make an edit there, we can see how it affects the call site on the left.
As mentioned in my list of pros & cons, a very common cause of bugs is editing a function that's used in several places, and changing it in such a way that we introduce a bug at another call site that we didn't look at. So I think it could be really helpful if a tool is able to show how our change affects not just one call site, but several, maybe all of them. But I'm not sure yet what the design of that should look like. Maybe on the left side we can flip through all the callers. Hm, this is starting to sound similar to my call graph navigator from Episode 4! Maybe that idea and this idea could be unified to a greater whole? I don't know yet.
One disadvantage of this expanding expanding expanding, is that each time we expand, the indentation grows. Pretty soon, the left half of our screen is just whitespace.

But I think the tool could mitigate that, too. Just have the tool automatically scroll to the right, to align the least deeply nested row on screen precisely to the left edge.

In the prototype, I kinda cheated and I had at most 1 function call per line. But in real code, there may be more. If there are two function calls on the same line, the user should be able to expand either one. Instead of a single plus sign in the left margin, how should the user choose which one to expand? Could they both be expanded, or just one at a time?
And in the argument-name substitution, what if an argument is neither a variable, nor a hardcoded constant, but a long complex expression, or another function call? What's the nicest way to substitute that into the function body? If we were to just inline the long complex expression in multiple places, it would be repetitive and maybe make the code harder to read. Maybe in this case it should still be mapped to the parameter name instead of inlined everywhere?
Finally, let's dream about the future. By now, we see that functions and blocks are really quite similar. Wouldn't it be nice if they were really the same thing? I mean, not in C#, but in some future programming language and tool. Tell me what you think.
If you're watching these talks as I release them and not far into the future, you should know that there's gonna be a longer gap before the next one. Maybe a few months. I need time to make some prototypes. Please leave feedback, and bye!